Series note: This post is part of my AI ABAP development series, where I go from AI development in general, to ABAP-specific problems, and then to ARC-1.
In the first post of this series, I wrote more generally about how I use AI today, why context matters so much, and why I am still not fully convinced by the more maximalist agentic hype.
Here I want to get more concrete. Because SAP development is not one thing, and that matters a lot for AI.
There is a big difference between UI5 or CAP development with AI and ABAP development with AI. If I mix those together, then the whole discussion becomes too vague very quickly.
For me this comes down to three questions:
- How does the model get the needed context?
- Where does the writing happen?
- Who is actually in control of that setup?
I want to answer those questions in this post.
SAP development is not one thing
When people talk about “AI in SAP development”, a lot of very different things get mixed together.
UI5, Fiori, CAP, BTP extensions, ABAP Cloud, ABAP on a shared dev system, Joule in Eclipse, MCP servers, local git workflows, sandbox systems, custom code migration. All of that gets thrown into one big AI bucket.
But these are not the same problem. The reason I want to split this early is simple: some SAP development areas already fit quite naturally into AI assisted workflows, and some really do not.
If I do not separate that clearly, then the discussion becomes too vague very quickly.
Why UI5 and CAP already feel much more natural
For frontend work like UI5, Fiori, CAP, or generally JS and TS based development, AI usage already feels much more normal. The development is usually off stack. You work in local files, use git, open pull requests, run CI/CD pipelines, let tests run, get peer review, and only then move the change further. If AI does something weird, it is annoying, but usually not catastrophic, because there are already good gates in this ideal process.
That is also why GitHub Copilot in VS Code became pretty normal in a lot of companies. If you combine that with good context, for example docs from SAP Help or SAP Docs through MCP, then you can already move quite fast today. I use my own sap-mcp-docs server a lot for exactly that. SAP also moved in that direction with MCP servers for UI5, CAP, and Fiori.
In that environment the three questions above are much easier to answer:
- Context comes from local files, documentation, and existing dev tooling.
- Writing happens locally, not directly in a shared SAP system.
- Control already exists through git, reviews, tests, and pipelines.
So the main question there is often more about workflow quality than about technical possibility.
Why ABAP is structurally harder
In the ABAP world things look different. The two main problems are the architecture and the tooling.
ABAP development is usually on stack. That means if you develop on the dev system, every change is directly applied to that shared system and can affect other developers as well. Even without AI that is already something you have to be careful with. With AI it becomes more sensitive, because a wrong write action is not just a wrong local file edit.
The second problem is tooling. A lot of ABAP developers still use SE80. Eclipse has been there for a long time, but if you were never forced into newer development models like RAP, a lot of people just stayed where they were. And if your main world is still SE80, then there is not really much serious AI support there.
So if I compare UI5 and ABAP, the problem is not only “does the model know ABAP”. The bigger question is in which environment this happens at all, and what happens if the model is wrong.
That is also why I think the SAP Community post The agentic revolution is here, and your ABAP code is the foundation fits quite well here.
The point there is not really that agents replace ABAP. It is more that if agents are going to call into SAP systems, then your ABAP foundation matters even more. Interfaces, CDS views, checks, naming, error handling, package structure, all of that becomes important.
The better and clearer your ABAP foundation is, the more useful and safer the agent layer on top can become, because they use your ABAP code as the foundation for their work.
Model choice still matters, of course. I already wrote two separate posts around ABAP code generation and ABAP understanding, and my practical takeaway is still that strong general models together with better tooling and grounding are currently the better path than hoping one SAP specific model alone solves the problem. But even with a better model, the structural ABAP problem stays the same: on stack writes, shared systems, and weak control do not disappear. Frontier models are just better to handle more complex problems as with complexity comes usually a larger context to handle, and frontier models are usually better at that.
The three questions matter more than the hype
I think this is also why Agentic Engineering Patterns from Simon Willison fits so well here.
What I like there is that “agentic” is not treated like some magical category. It is more a set of working patterns: tools in a loop, tests, boundaries, anti-patterns, habits, and when not to let the loop run too far. For ABAP this matters even more, because the question is not only if an agent can do something, but what kind of loop you actually allow it to run against a real SAP system.
So for every pattern below I want to keep asking the same three questions:
- How does the model get context?
- Where does writing happen?
- Who controls that setup?
Current patterns for AI assisted ABAP development
Lars Hvam wrote a very useful paper on the patterns for using LLMs in ABAP development. You can read more details and see diagrams there.
I like that framing because it avoids the fake discussion of “one right way”. There is not one right way. There are different patterns with different tradeoffs depending on your landsacpe, knowledge, and setup.
1. IDE integrated AI in Eclipse
This is the most obvious option. You stay where you already work and let the built in AI features help with explanations, code suggestions, tests, and smaller implementation tasks. Depending on landscape and setup, that could mean Joule for Developers, GitHub Copilot in Eclipse, or Amazon Q Developer for Eclipse.
- Context: Mostly the currently selected SAP object plus what the IDE integration can access or what you add manually.
- Writing: Directly to the SAP system.
- Control: Mostly on the developer side, not much central boundary around the agent loop itself.
This is easy to adopt as “quick win”, but it does not solve the core architecture problem.
2. VS Code, today mostly with ABAP Remote FS and soon also with SAP’s own extension
This gives a much better AI developer experience because VS Code is simply ahead in that area compared to Eclipse. Today that usually means community tooling like ABAP Remote FS. But SAP’s own ABAP Cloud Extension for VS Code is planned for Q2 2026, so likely around May if that timeline holds. That means ABAP Remote FS is probably more of a bridge than the long term answer, at least for the scenarios SAP will cover first.
The problem stays similar though. If the setup writes back directly through ADT APIs, then the nicer editor experience still does not remove the main risk.
- Context: Better local editor experience, but still tied to what the tool can read from the system.
- Writing: Still directly to the SAP system.
- Control: Still relatively weak if the whole setup sits with the individual developer.
So the nicer developer experience does not remove the main risk.
3. ADT MCP Server
This is where things get really interesting.
With an ADT MCP server the AI does not just see files. It gets structured tools. It can read objects, search code, inspect context, run checks, navigate references, write changes, etc., depending on what the server allows.
This is also currently one of the best ways to solve the context problem.
I already wrote earlier about this direction in Finally: An MCP Server for ABAP, and since then the space has grown a lot. That is also why I keep SAP MCP Servers: The Missing Overview around, because the number of SAP MCP servers and adjacent tools is growing quickly enough that it is easy to lose track.
The AI can say: I have a problem in this class, now get me the class, then maybe read the related table, check another class, search similar code, maybe combine that with SAP documentation from another MCP server like sap-mcp-docs, and build up the context automatically. That is really useful.
- Context: Very strong, because tools can gather much richer SAP context such as objects, data, and logs.
- Writing: Potentially directly to the SAP system.
- Control: Depends entirely on how the MCP server is designed, configured, and deployed.
This is exactly why the MCP path is so interesting and so dangerous at the same time.
It solves a real problem, but it also raises the control question much more sharply. It is also why SAP’s post on Standardizing AI Tool Integration with MCP matters. MCP in SAP is not just some hobby side path anymore. It is becoming part of the real architectural conversation.
4. Sandbox systems
In my opinion this is one of the safest options.
Give the AI a sandbox system that can be isolated, reset, or recreated, and suddenly much more becomes possible without damaging the shared dev system.
- Context: Very strong, because the AI can still inspect and work against a real SAP system.
- Writing: Direct, but only into an isolated system.
- Control: Much better than shared-system direct access, but with infrastructure cost and operational overhead.
This is a very good pattern if you can afford it. The problem is that most teams do not have this luxury.
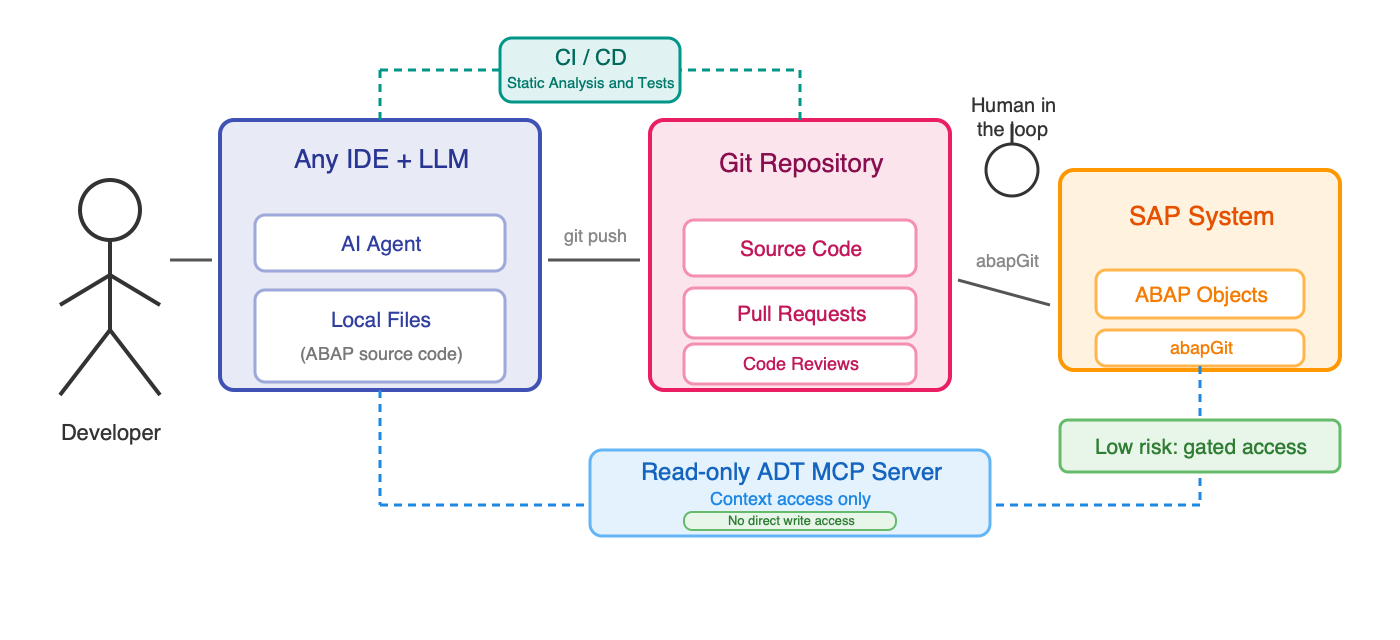
5. Git or off stack development with abapGit and CI/CD
In many ways this is the cleanest approach.
The AI never writes to the SAP system directly. It writes local files, then git, review, checks, and pipeline steps become the gate.
- Context: Depends on what additional read access you give the AI.
- Writing: Local first, not directly on the SAP system.
- Control: Much stronger, because review and automation become the boundary.
This is how a lot of frontend development already works, and it is much easier to trust.
The problem is that many ABAP teams are simply not there yet. If there is no clear package separation, no git workflow, and no pipeline culture, then introducing this only for AI becomes a bigger transformation project.
6. Hybrid approach
This is the pattern I find currently the most practical long term.
The AI works locally or off stack, but still gets read access to the SAP system through ADT or MCP for context.
That means it can understand the actual system better, but the writing still happens in a gated git flow.
- Context: Strong.
- Writing: Gated.
- Control: Much better than direct write access, while still preserving real system context.
For me this is one of the most promising directions.
Read access already gives a lot of value
One thing I find important here is that AI does not need direct write access to be useful. For many real problems, reading and analysis can already take away maybe 80 percent of the work. If an issue comes in, the first question is usually not “who writes the line of code”, but “where is the actual problem”. If the AI can analyse the system, narrow it down, read code, data and logs, suggest where the bug is, and maybe propose the one line change, then the developer can still do that actual line manually. Or the AI writes the proposed fix and the developer still copy pastes it, reviews it properly, and tests it. That alone is already a lot of support.
And this read access is not only useful for developers who want to code faster. It can also help people working more on architecture, specifications, analysis, testing, and migration. If they can read how the system works, where logic is implemented, how much something is used, or what the dependencies are, then that already helps a lot, for changes, fixes and the transformation from ECC to S/4HANA.
That is also why I do not really buy the simple management idea that you just give everyone Copilot or an Agentic AI coding tool and suddenly everyone codes much faster. That is not the real point.
The bigger question for me is how to help ABAP developers and SAP teams in their daily work with things like:
- faster problem analysis
- less wasted time searching for the right place
- easier access to relevant documentation, logs, and data
- faster understanding of old logic
- better support while writing specs and tests
An MCP server for documentation, an MCP server for SAP access, and access to more internal documentation can already help a lot here without giving full write access to everything.
What current setups still do not solve
So where is the actual gap today?
For me it is not that AI cannot write ABAP. It can. It is also not that AI has no SAP context at all anymore. That situation is improving a lot through ADT tooling, MCP servers, documentation access, and better models.
The real gap is that context access, write access, and control are tied much more closely together in ABAP than in off stack development, and that becomes an enterprise problem very quickly.
What is often still missing is some combination of proper read-only defaults, operation boundaries, package restrictions, blocking dangerous features like free SQL, per-user identity instead of shared technical access, auditing, and a setup that security, basis, and development can all still trust.
That is also why I am skeptical of setups where powerful ADT MCP servers simply run locally on the laptop of an individual user. If someone can set it up, and usually that is not even that hard, then suddenly you have a very powerful bridge from the model into the SAP system, but without much admin oversight around it. In an enterprise landscape that is not ideal at all.
What an ideal setup would look like
So for me the question is not if agentic ABAP development is possible. It already is.
The more important question is what a setup would need to look like if it should actually work in enterprise reality.
For me that ideal direction is something like this: strong read access to real SAP context, useful structured tools instead of blind file edits, write access that is either gated or at least strongly restricted, central deployment instead of every user doing their own thing locally, clear identity handling, auditability, and enough safety boundaries that basis, security, and development can all live with it.
That does not mean every team needs the exact same architecture. But it does mean the next step cannot just be “give the model more power and hope for the best”.
Why this matters for the next post
The next post is where I want to look at what a more enterprise-ready ADT MCP setup should actually provide if you take those problems seriously from the beginning.