Series note: This post is part of my AI ABAP development series, where I go from AI development in general, to ABAP-specific problems, and then to ARC-1.
In the first post of this series, I wrote about context and how I use AI in development. In the previous post, I then moved that discussion into ABAP and ended more or less with one question: what would an ADT MCP setup need to look like if you take control, identity, and security seriously from the beginning?
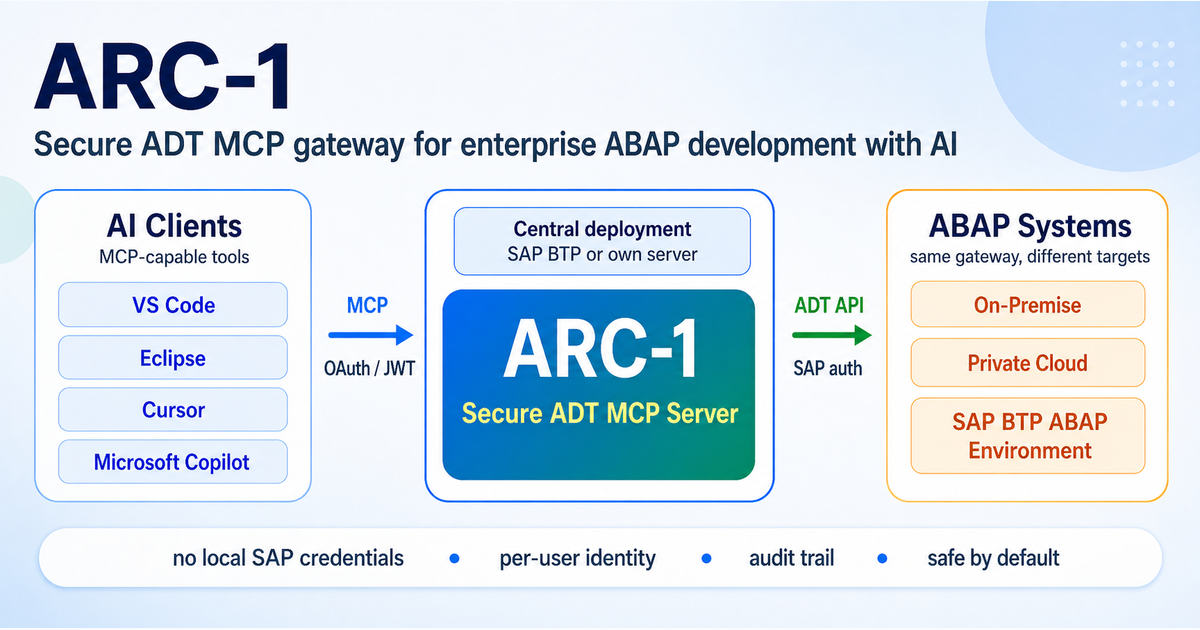
This post is my current answer to that question. It is called ARC-1 (ABAP Relay Connector, pronounced arc one [ɑːrk wʌn]), and yes, it is another ADT MCP server. But the important difference is not that it can talk to ADT at all. Other projects already showed very well that this is possible and useful. The difference is the architecture and the focus, which is also why the ARC-1 documentation spends a lot of space on security, authentication, deployment, and operations, not only on the tool list.
Why ARC-1 had to exist
Luckily, the community already did a lot of the hard work before ARC-1. Marcello Urbani’s abap-adt-api gave many TypeScript projects the foundation to work with ADT APIs at all, which are still not really documented in a useful way. Projects like oisee/vibing-steampunk, fr0ster/mcp-abap-adt, and DassianInc/dassian-adt already proved that MCP and ABAP development can work in practice and can be very useful. And Wouter Lemaire’s btp-sap-odata-to-mcp-server was also important for me, because it already showed a BTP-deployed and centrally managed direction much earlier, and Wouter also helped me during the ARC-1 implementation.
So ARC-1 is not me claiming that nobody solved this before. For me it is more this: the others already proved the technical possibility, and ARC-1 is my attempt to close the enterprise gap. That gap is the same one I described in the last post. In ABAP, the hard part is not only getting context into the model. It is that context access, write access, and control are tied very closely together in a real SAP landscape.
That is why I did not want to build just another local developer tool that happens to speak MCP. I wanted to build a secure ADT MCP server with a clearer security concept, more central control, and an architecture that fits better into enterprise SAP environments.
Central instead of local
For me this is probably the biggest architectural difference. Most current MCP ADT setups are still mainly local. The server runs on the developer laptop, gets configured there, stores credentials there, and then talks directly to the SAP system from there.
That is fine for trying things out. It is also fine for fast experimentation. And to be clear, ARC-1 can also run locally. That is useful for tests, local development, and simply trying the server out. But local developer setup is not the main story I care about here. The main story is central deployment.
That means one managed ARC-1 instance per SAP system, with central configuration, central security settings, central logging, and a clear operational owner. That can run on a company server, in Docker, or ideally on SAP BTP Cloud Foundry. The architecture documentation goes into the technical flow in more detail, but I will go much deeper into the BTP side in the next post, because that deserves its own post.
For me BTP is especially interesting here because it lets you reuse things that already exist in many companies anyway: XSUAA, destinations, Cloud Connector, audit services, role assignment, and the usual BTP login flow. Then the developer mostly just needs the MCP URL and the standard login, while admins and authorization teams keep control in the place where they already work.
I also do not think this is only an SAP-specific thought. Salesforce is already moving in a similar direction with hosted MCP servers and Headless 360, where more of the platform is exposed as APIs, MCP tools, or CLI commands. To me that confirms that enterprise MCP is a platform and governance topic, not only a developer convenience topic.
The reason this matters is simple. If the MCP server sits only on the laptop of an individual developer, then the architecture is also controlled there. That is exactly the part I do not find convincing for enterprise usage.
Two auth hops matter
One thing that became very clear while building ARC-1 is that there are really two completely different authentication questions. The first one is who is allowed to talk to the MCP server at all. The second one is as which user the MCP server talks to the SAP system.
That sounds obvious, but many discussions around MCP servers blur those two things together. In ARC-1, these are treated as two separate hops: MCP client -> ARC-1 and ARC-1 -> SAP. This matters because the architecture becomes much clearer after that.
For the first hop, ARC-1 can use things like API keys, OIDC/JWT, or XSUAA OAuth, depending on how and where it is deployed. For the second hop, ARC-1 can talk to SAP with Basic Auth, BTP service keys, or with Principal Propagation, depending on the target landscape.
That split is very important for enterprise usage, because it lets you separate client access control from SAP identity handling instead of hiding both behind one local config file. It also makes it easier to support different use cases. If ARC-1 is used more like a backend connector for an automation, an API key may be totally fine. If real per-user identity matters, then OAuth or XSUAA plus Principal Propagation is the much more interesting setup.
Safe by default, not allow all by default
The next big difference is that ARC-1 starts from the assumption that the default should be restrictive. Out of the box ARC-1 is read-only. It blocks free SQL. It blocks named table preview. It does not expose transport actions unless those are enabled. And even if writing is enabled, writes are still restricted to $TMP unless packages are explicitly allowed.
That last point is important to me. Yes, it makes the first setup a bit less magical. Sometimes you need to configure one more thing. But I prefer that over accidentally giving an AI assistant full write access to transportable packages because one flag was too broad.
ARC-1 also has operation allowlists and denylists, package restrictions, and safety profiles like viewer, viewer-sql, or developer. So there is not only one on or off switch. For SAP development that feels much more realistic to me than a server that starts by allowing everything and then hopes people will restrict it later.
Layered security, not just one switch
This also leads to the next point. For me, security here is not one boolean setting. It is several layers on top of each other.
At the ARC-1 level there is the server safety configuration itself: read-only mode, blocked SQL, package restrictions, operation filters, transport gates. Then there is the identity and role layer on top, for example via OIDC or XSUAA scopes and roles. And then there is still the SAP system itself with its own authorization objects and checks.
That means all of these layers have to allow something before it actually happens. If ARC-1 is configured read-only, then even a user with a more powerful role still cannot write. If a user has write scope in ARC-1, but the SAP backend authorization is missing, the write still fails.
That is exactly how I want it. ARC-1 should not replace SAP authorization. It should add another control layer in front of it.
Per-user identity matters
This becomes even more interesting once you look at per-user identity. One of the things I wanted very early is that ARC-1 should not force everything through one shared technical SAP user if that can be avoided.
That is why Principal Propagation is such an important part of the architecture for me. If Principal Propagation is active, the MCP user identity can flow through ARC-1 and into SAP, so that the action runs with the real SAP user and the real SAP authorization of that person. I already tested this and it works.
That is important not only because it is cleaner technically. It is important because it fits much better into audit, compliance, and real enterprise authorization models. I do not want the whole architecture to end in “trust this one service account and hope nobody asks too many questions later”. I want the system to be able to say who actually did what.
Audit logging is part of the feature, not an afterthought
The same applies to audit logging. If AI is allowed to read from or write to a real SAP system, then logging is not some optional extra feature. It is part of the basic architecture.
ARC-1 emits structured audit events and can integrate with the BTP Audit Log Service. That means you can log who called which tool, what happened, and in which request context it happened. Especially on BTP, that gives you a much better compliance story than a local MCP server that mostly lives on one laptop.
For normal hobby tooling this might feel like overkill. For SAP it does not. Especially if the recommended target architecture is BTP, it makes sense to also use the established platform services for logging and identity instead of building a parallel side world around them.
Not locked into one client
This point is also important to me personally. There are already many useful prompt files, local plugins, slash commands, and client-specific workflows around SAP and ABAP. I do not think that is wrong. A lot of that work is useful and practical.
But that is still a different architecture. Very often the logic, the access, and the credentials live mainly on one laptop and inside one AI client. For enterprise usage I want the opposite.
I want one secure ADT MCP server that can be used from many clients. That can be Claude, GitHub Copilot, Copilot Studio, IDEs, or later other MCP clients that also support OAuth. In the best case, that can then be combined with Principal Propagation instead of local SAP credentials.
That flexibility matters, because in many companies the default AI developer tooling will not be Claude Code. It will more likely be GitHub Copilot or other centrally managed tools. And I do not want the SAP side of the architecture to depend on one specific AI client. MCP is useful exactly because it decouples those things.
Testing matters more here than for normal dev tooling
I also want to stress the testing part, because for a project like this it matters a lot.
If an MCP server only works in one perfect demo system, then that is not enough. SAP systems are messy. Different releases behave differently. Different endpoints exist or do not exist. BTP ABAP is different again. And error handling around ADT is not always beautiful.
That is why ARC-1 puts a lot of effort into testing. Right now the project has more than 1,300 unit tests, plus integration tests and E2E tests that execute real MCP tool calls against live SAP systems. As a freelancer I obviously do not have access to every possible enterprise landscape, but I do test against real systems. I test against BTP ABAP, the ABAP trial system in Docker, and the older 7.50 trial system.
I also do not test only with one ideal model and one toy example. I try it myself with stronger and weaker models and with workflows that are much closer to reality. That includes things like clean core analysis or creating a full RAP project from nothing, not even a table, up to an activated RAP project you can actually use. A lot of the workflows and feature ideas behind that are also visible in the ARC-1 skills catalog, because those are more or less the kinds of use cases I want to make work reliably.
For me that is also one of the big lessons from working with SAP tooling in general: if you do not test against real systems, you often only test your assumptions.
So yes, this is another ADT MCP server
And that is fine. I do not think ARC-1 needs to exist because every other project is wrong. Quite the opposite. The other projects created the category, pushed the ecosystem forward, and showed there is real interest.
At the same time I think ARC-1 is different enough in architecture and focus that it makes sense right now. It is especially different from the angle of secure defaults, central deployment, layered security, per-user identity, and auditability.
And yes, it may also differentiate itself from the future official SAP approach depending on how that evolves. As of SAP’s November 4, 2025 announcement about the next era of ABAP development, SAP plans an official ABAP MCP server for Q2 2026 together with the ABAP language server and related SDK pieces in VS Code. I think that is good news.
Actually, that is also the point where building yet another ADT MCP server becomes harder to justify long term. If SAP publishes the language server and SDK in a reusable way, then the right move would be to reuse the same foundation that the official SAP MCP server and Eclipse tooling use instead of reimplementing more and more HTTP details on the community side.
If SAP ends up shipping a server with a similar architectural direction, broad system coverage, and the same kind of enterprise features, then there may eventually be no strong reason for ARC-1 to continue. For me that would still be a win.
The point is not that my server must win. The point is that there is clearly a gap today, the community is filling it, and competition is usually good. It helps people choose, it helps ideas spread, and ideally it also helps SAP learn from what the community already built. Until then, people can decide on their own if ARC-1 is useful for them.
A note on ADT APIs and SAP’s new API policy
There is one more point worth separating from the architecture discussion. SAP published a new API policy in April 2026, and some practical implications still need clarification, especially for SAP customers, partners, and community tools that build on top of SAP development APIs.
For ADT, the publicly available material points to a more nuanced situation. SAP provides an official ADT SDK with JavaDoc, and the ADT download page describes it as a public API to implement or integrate your own tools with SAP’s ABAP IDE. There is also an SAP document about creating and consuming RESTful APIs in ADT. This does not imply that every internal /sap/bc/adt endpoint is covered by the same support boundary, but it does show that parts of the ADT tooling and communication model are documented and intended for integration scenarios.
This is also relevant to what SAP wrote in the discussion around the new ABAP Development Tools for VS Code. SAP described the ABAP language server as something like an “ADT SDK 2.0” and mentioned plans to release it as a standalone component after the first VS Code extension release. A standalone release could make the support boundaries clearer for community tools, CLIs, MCP servers, and other integrations. Until more detailed guidance is available, the main point is to track SAP’s policy and documentation closely and adjust implementations when specific activities are clarified as unsupported or not permitted.
Why this matters for the next post
In this post I mainly wanted to explain why ARC-1 exists at all and why it looks the way it does.
The next post is where I want to go deeper into the BTP side, because that is where the architecture becomes much more interesting in practice: XSUAA, Destination Service, Cloud Connector, Principal Propagation, and how this can fit into a real enterprise setup instead of just a developer laptop.
Discuss this post
References & links
- ARC-1 on GitHub
- ARC-1 Documentation
- ARC-1 Architecture
- ARC-1 Authentication Overview
- ARC-1 Security Guide
- How I Use AI for Development and Why Context Matters
- ABAP and Agentic AI: The Hidden Problem in Real Projects
- Marcello Urbani: abap-adt-api
- Wouter Lemaire: btp-sap-odata-to-mcp-server
- oisee/vibing-steampunk
- fr0ster/mcp-abap-adt
- DassianInc/dassian-adt
- ARC-1 Skills Catalog
- Introducing the Next Era of ABAP Development
- SAP API Policy
- ABAP Development Tools SDK
- Create and Consume RESTful APIs in ADT
- ABAP Development Tools for VS Code discussion