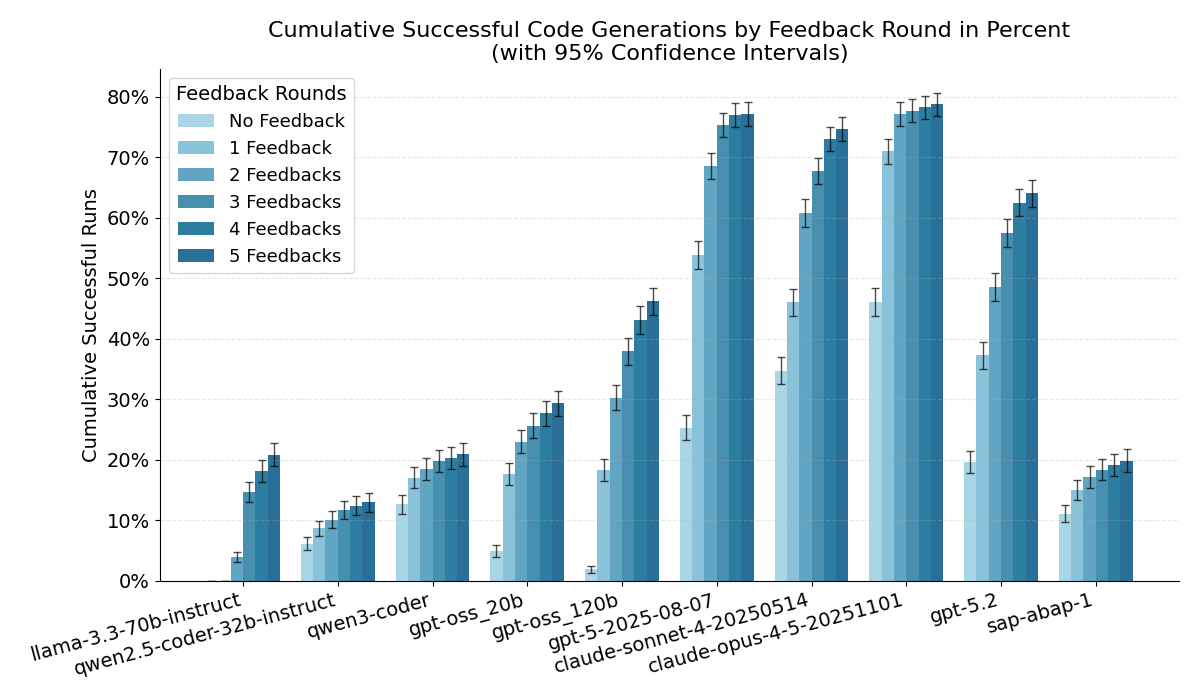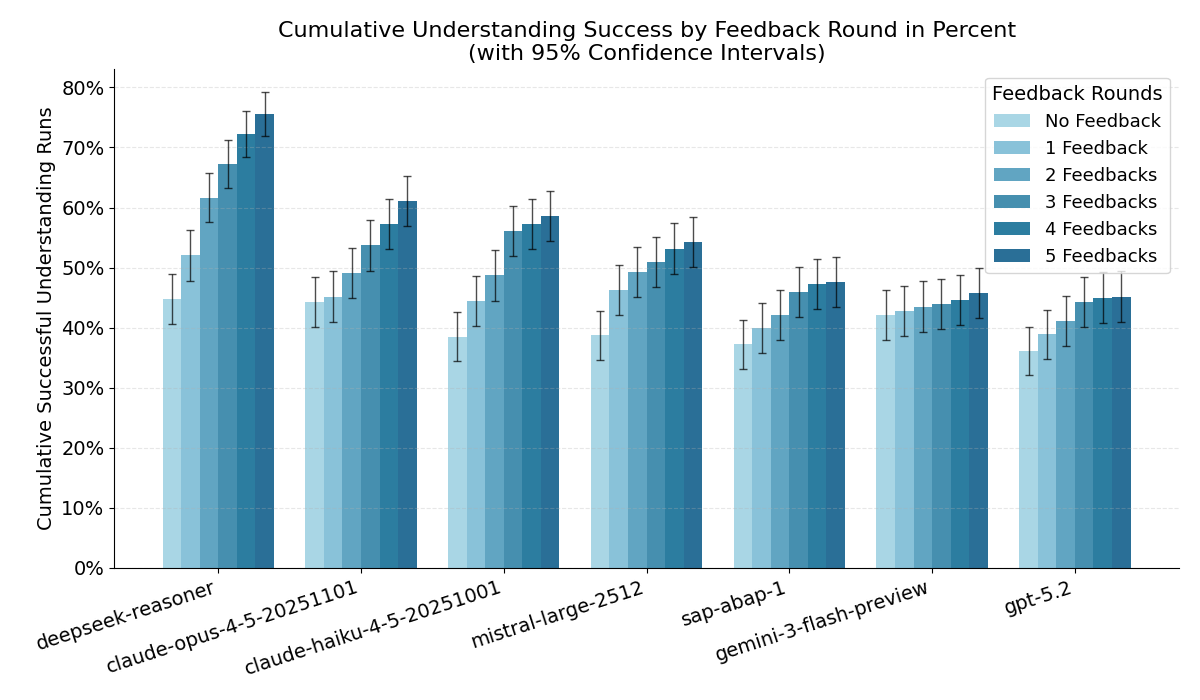
SAP’s ABAP-1 Loses Every ABAP Benchmark, Even “Explaining”
Previous post (code generation benchmark): Benchmarking LLMs for ABAP Live benchmark results (old + new): abap-llm-benchmark.marianzeis.de In my first evaluation (based on the TH Köln benchmark paper), I extended the original setup with additional models and focused on a very concrete question: how well can LLMs generate ABAP code that actually compiles and passes ABAP Unit tests? I also tested SAP’s model ABAP-1, and it performed very poorly for code generation. To be fair: SAP also states this in the documentation. ABAP-1 is primarily meant for explaining ABAP code not for reliably generating full working implementations. ...